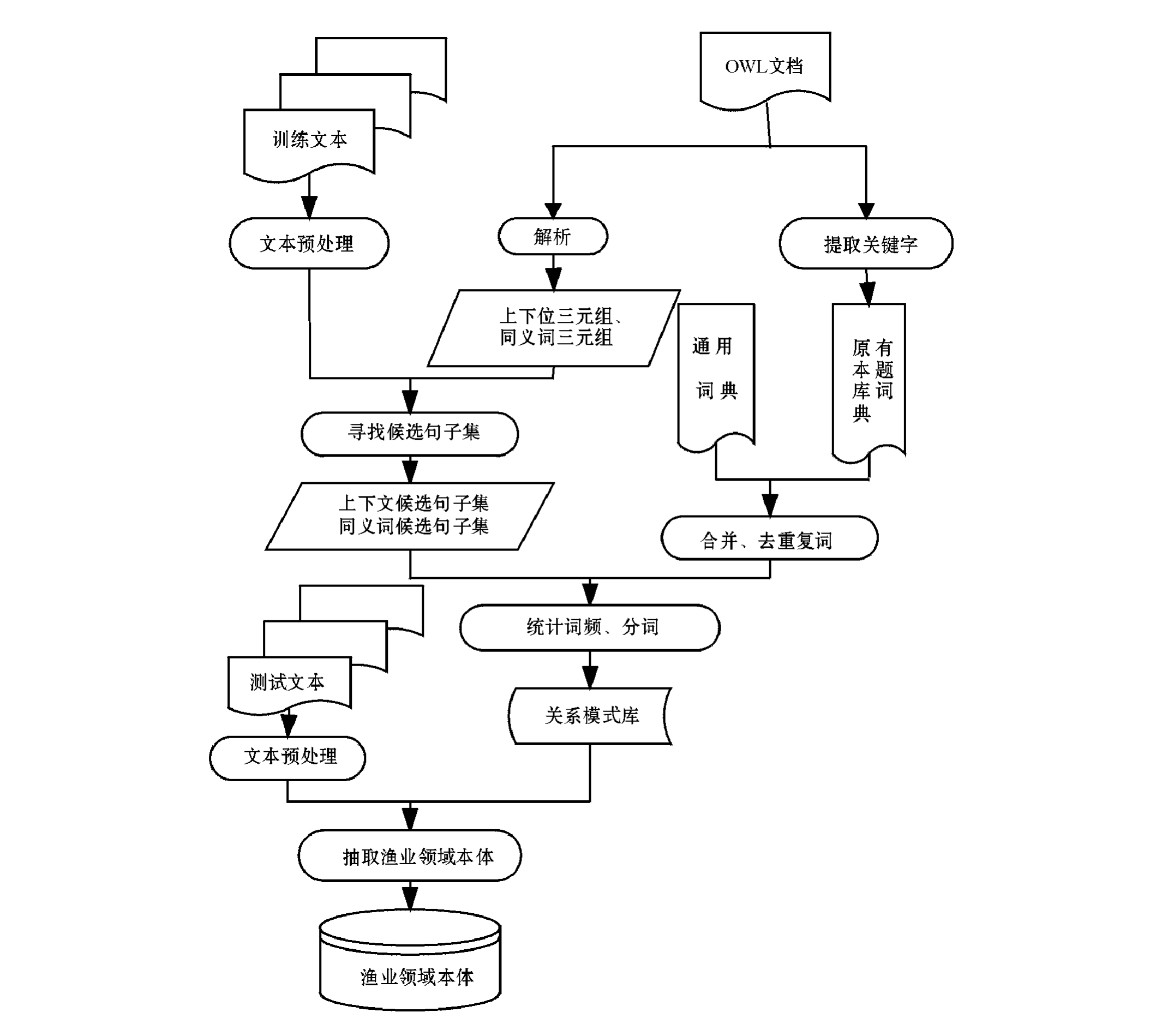
图1 本体学习的基本流程
Fig.1 Basic flowing diagram of ontology learning
于红,刘溪婧
(大连海洋大学信息工程学院,辽宁大连116023)
摘要:分析了现有本体学习方法的基本思想及其应用于渔业领域本体学习的局限性,结合渔业领域概念的特点,提出了一种基于知识库的渔业领域本体学习算法,给出了算法的详细描述,并用实验验证了算法的性能。结果表明,该算法的召回率较高,但准确率稍低一些。
关键词:知识库;本体学习;渔业本体
作为一种知识表示方式,本体被广泛应用于领域搜索引擎、语义Web、智能信息集成和知识管理等领域[1]。在建立渔业搜索引擎过程中,渔业领域本体对提高搜索引擎的查全率和查准率起到重要的作用。然而领域知识并不是一成不变的,它会随着时间的推移而不断变化,因此最初建立的本体库需要不断更新[2]。初始的渔业领域本体库是在综合了若干渔业领域专家的意见之后采用手工方式建立的。用手工方式建立和更新本体是一项庞杂而乏味的工作,而本体的更新则是一个连续的工作。用手工方式更新渔业领域本体需要不断地与渔业领域专家沟通,在实际应用中有一定困难,因此,渔业领域本体的更新成为渔业领域本体应用的瓶颈。要想解决这一瓶颈,就必须研究渔业领域本体学习算法,采用自动或半自动的方法对渔业领域本体库进行更新,这对促进渔业领域本体的应用有着非常重要的意义。
本研究中,作者通过对基于知识库的渔业领域本体学习算法的相关工作进行分析,阐述了基于知识库的渔业领域本体学习算法的基本思想,并用实验验证了该算法的效率。
本体学习的相关研究在欧洲开展得较为广泛。Maedche等[3]最先描述并评价了将关联规则应用于本体学习的方法。Stojanovic等[4]通过考察数据库中的表、属性、主外键和包含依赖关系,给出了一组从关系模型到本体的映射规则。基于这些规则能够直接得到一个候选本体,然后进一步对该候选本体进行评价和精炼,生成最终的本体。Astrova[5]提出,由于HTML表格是Web上用户和数据库交互最常用的界面,所以在无法获得数据库模式信息的情况下,可以通过分析这些HTML表格的结构和数据来获取关系数据库的语义,从而构建本体。高军等[6]提出了一种基于Ontology的半自动Web内容精确二阶段提取的方法,在提取过程中利用上下文无关文法来表示并提取HTML节点内部数据,使得数据提取的粒度更小,提取精度更高,是一种有监督自学习的方法。方卫东等[7]为获取领域本体并量化概念关系的可信度,提出了一种基于Web挖掘的学习模型。通过可扩展的模式集和分布语义模型获取本体主干,使用关联规则发现概念间的一般关系,对候选本体进行修剪和合并。模式可信度、概念语义距离与关联特征决定了概念间关系的可信度。综合分析上述本体学习算法,不难发现,现有的本体学习算法要么采用数据库属性中包含的语义信息来进行本体学习,这需要有特定数据库的支持;要么用关联规则来进行本体学习,关联规则对学习概念间的相关关系效果较好,但是对概念间关系种类的确定还需要人工干预,因此关联规则是一种半自动本体学习方法。
渔业领域本体库中概念间的模式规律性比较强。既然已经建立了渔业领域本体库,则可利用本体库中的本体从语料中学习渔业领域概念间的关系
模式来发现新的本体,以完成本体更新工作,这是一种有效的本体自动更新手段。
2.1 本体表示
本研究中建立的渔业领域本体库用OWL语言描述渔业本体,用Protégé 3.1.1作为本体建模工具,用手工的方式建立本体库,生成的本体是以OWL文件的形式存在[8]。
OWL文件可以用Protégé建模工具采用手工方式或者在应用程序中用Jane接口查询和修改,因此,查询和更新的效率受工具或接口能力的限制,在本体库较小的情况下,查询或修改操作的速度对系统性能的影响不是很明显。随着本体库的不断更新,本体库的规模会逐渐增加,查询操作的速度对系统性能的影响很大。为了能对本体库进行有效索引,提高对本体库的操作效率,需要修改本体的表示方式。本研究中以三元组的形式来描述渔业领域的概念及概念间的关系,同时本体学习算法中需要进行OWL文件到三元组文件的转换。
三元组是由OWL文件转换而来的,三元组的基本格式为〈概念1,概念2,关系〉,在进行具体应用时可以分别对关系、概念、概念对进行索引。
2.2 基于知识库的本体学习基本流程
基于知识库的本体学习流程如图1所示。
图1 本体学习的基本流程
Fig.1 Basic flowing diagram of ontology learning
(1)三元组的生成。将OWL文件解析成三元组形式,每个三元组包括一个概念对和一种关系,可以通过概念对以及相应的关系寻找关系模式。在进行转换时,根据OWL文件中表示关系的关键词确定概念之间的关系。如用关键词subClass约束的两个概念之间具有上下位关系,用same或sameas约束的两个概念之间是同位关系。除此之外,还有属性关系、不相交关系等。由于本研究中重点研究同位关系和上下位关系,因此只处理了这两种关系。
(2)原有本体库词典的生成。将已有的OWL文件转化为渔业领域的概念,目的是构建文本预处理和词频统计分词词典。
(3)文本的预处理。文本的预处理包括训练文本的预处理和测试文本的预处理,主要是去掉停用词以及某些标点符号等。
(4)关系抽取。包括候选句子集的生成和关系模式库的生成两个部分。其中候选句子集的生成是根据三元组在训练文本中提取出含有三元组中概念对的所有句子;关系模式库的生成主要是通过对候选句子集合进行分析并找到其中的模式。
(5)渔业领域本体的抽取。利用关系模式库里的模式,在测试文本中寻找符合这些模式的句子,并对这些句子进行分析,以找到其中包含的本体。
该流程中,关系抽取是整个算法的核心。
2.3 关系抽取
本体学习的任务之一就是在领域文集中识别出属于概念之间的关系。常用的概念间关系的获取方法有基于模式的方法、基于数据库的方法、基于关联规则的方法等。目前由于未找到可以用于渔业领域本体学习的渔业领域数据库,因此不能采用基于数据库的方法;基于关联规则的方法作为全自动的本体学习方法效果不好,因此也不能采用基于关联规则的方法;而渔业领域的本体库中概念间的模式规律性比较强,因此采用基于模式的方法学习渔业领域本体比较适合。为此,本研究中采用基于模式的方法获取概念间的关系。
关系抽取的基本思想为:对于本体库中用三元组表示的每一个本体,将训练集文本中同时包含三元组中概念对的句子抽取出来构成候选句子集合;然后,用统计学习加初步的语义结构分析的方法对句子集合中的句子进行分析,再把具有相同概念关系的模式提取出来,并统计各个模式出现的频率,将频率大于给定阈值的模式选为可用模式。本研究中只考虑两类关系:一类是上下位关系,一类是同位关系。关系抽取主要有两个子模块:候选句子集的生成和关系模式库的生成。
2.3.1 候选句子集的生成 根据上下位三元组和同位三元组分别提取训练文本中存在上下位和同位关系概念对的句子,最后输出的是上下位候选句子集和同义词候选句子集。算法描述如下:
算法CandidateSentenceGenerating
输入:经预处理后的训练文本集合、原有本体库
输出:带规则的候选句子集
//HyponymyCandidateSet是上下位候选句子集合,CoordinateRelationCandidateSet是同位候选句子集合
(1)初始化HyponymyCandidateSet和CoordinateRelationCandidateSet为空
(2)将本体库读入内存
(3)for(训练集中的每个文本)
(4)读入文本且进行文本预处理; (5)for(文本中的每个句子)
(6)for(本体库中的每个三元组)
(7)if句子中同时包含三元组中的概念对
(8)if该三元组属于上下位关系then将该句子放入HyponymyCandidateSet
(9)else将该句子放入Coordinate-RelationCandidateSet
(10)输出HyponymyCandidateSet和CoordinateRelationCandidateSet
2.3.2 关系模式库的生成 通过分析上下位候选句子集和同位候选句子集,用统计分析的算法,在经过分词处理后的句子中,统计出能表示两种语义关系的候选关系模式集,并设置阈值选择适量的模式,获得两种类型的语义关系,最终建立语义关系库。在计算词频时需要对文本进行分词处理,因此需同时加载渔业领域词典和通用词典。关系模式库生成算法描述如下:
算法PatternGenerating
输入:上下位候选句子集合HyponymyCandidateSet
输出:上下位模式集合HyponymyPatternSet
(1)初始化HyponymyPatternSet,CadidatePatternSet为空
(2)读入通用词典和领域词典
(3)for(HyponymyCandidateSet中的每个句子)
(4)对句子进行分词
(5)抽出概念对中间出现的词或者短语
(6)if该词或短语在CadidatePatternSet中then其出现次数自增1
(7)else将该词或短语加入CadidatePatternSe出现次数置为1
(8)for CadidatePatternSet中的每一个候选模式
(9)if出现次数>=阈值then将其放入HyponymyPatternSet
(10)输出HyponymyPatternSet
同位模式生成算法基本思想与此相同,因此不再赘述。
2.4 本体的获取
主要根据描述渔业领域本体库中概念之间关系的关系模式库,寻找和抽取结构符合这些模式的渔业领域本体。算法描述如下:
算法OntologyGenerating
输入:经预处理的渔业领域测试文本、同位关系模式库CoordinateRelationPatternSet、上下位关系模式库HyponymyPatternSet
输出:渔业领域本体库FishieryOntology
(1)初始化FishieryOntology为空
(2)for(测试集中的每篇文本)
(3)for(文本中的每个句子)
(4)if句子中包含CoordinateRelation-PatternSet中的模式then
(5)将该句子分词,找出该模式左右两侧的名词w1和w2
(6)将概念对〈w1,w2〉和关系类型has-a写入FishieryOntology
(7)if句子中包含HyponymyPatternSet中的模式then
(8)将该句子分词,找出该模式左右两侧的名词w1和w2
(9)将概念对〈w1,w2〉和关系类型is-a写入FishieryOntology
(10)输出FishieryOntology
(1)渔业领域文档的选取。因没有公开发布的渔业领域语料库,所以需要自己构建语料库。为了能检验算法的真实性能,实验文档的构建与实验算法设计是分离的。训练文档和测试文档都是委托大连海洋大学图书馆负责渔业领域资料管理的老师整理,他们从中文期刊全文数据库中找到500篇具有典型的渔业领域特征的文档,并将其中包含的同位关系和上下位关系进行了标注。本研究中选用其中的300篇作为训练文本,200篇作为测试文本,测试文本中标注的同位关系有180对概念,上下位关系有150对概念。
(2)词典的选取。本研究中用到两个词典:通用词典和渔业领域词典。其中,通用词典采用课题组自建的包括10万单词的词典;渔业领域词典是将课题组建立的渔业领域词典与渔业领域本体库进行合并后得到的。
(3)实验软硬件环境。本研究中采用的编程语言为Java,开发环境为JDK1.5,Eclipse3.2。CPU为Intel(R)Core 2,2.8 GHz,内存2 GB。
(4)实验结果评价。本研究中采用召回率和准确率来评价实验结果。定义如下:
召回率=(系统返回的正确概念对数目/测试文本中所存在的总的概念数目)×100%;
准确率=(系统返回的正确概念对数目/系统返回的所有概念的总数)×100%。
同位关系和上下位关系所选择的训练文本和测试文本相同。对300篇文档进行训练之后,满足条件的同位关系模式和上下位关系模式见表1。
表1 同位关系模式、上下位关系模式及出现频次
Tab.1 Coordinate relation pattern,hyponymy pattern and frequency

同位关系coordinate pattern模式pattern上下位关系出现频次出现频次frequency hyponymy pattern模式pattern frequency又称have another name called30是一种is a21学名formal name16包括include10作为to be6含有contain8成为to become5主要有as follows mainly7俗称be commonly referred to as 4
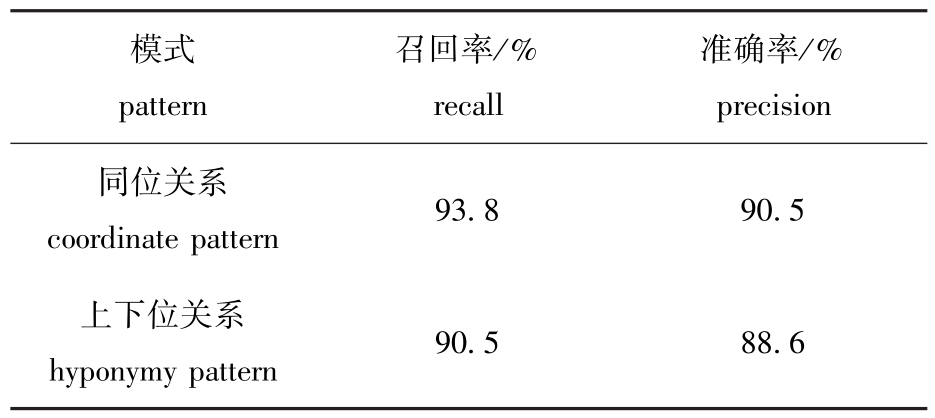
用训练之后的模式集对选定的200篇文档进行测试,同位关系和上下位关系的准确率和召回率如表2所示。
表2 召回率和准确率
Tab.2 Recall and precision
precision同位关系coordinate pattern模式pattern召回率/% recall准确率/% 93.890.5上下位关系hyponymy pattern 90.588.6
由于渔业领域的概念间的关系规律性较强,多数本体都满足一定的模式,因此,该算法的召回率较高。但是,由于模式中出现的词并不是在任何情况下都是描述概念间的同位关系或者上下位关系。如“张睿作为一名共产党员”中,张睿和共产党员不具有同位关系;“水中含有泥沙”中,水和泥沙不具有上下位关系。该算法不能区分这些情况,因此导致准确率较低。
本研究中,作者分析了研究渔业领域本体学习的必要性,概述了现有的本体学习方法的基本思想及其应用于渔业领域本体学习的局限性,结合渔业领域概念的特点,提出了一种基于知识库的渔业领域本体学习算法,给出了该算法的详细描述,并用实验验证了该算法的性能。实验结果表明,该算法的召回率较高,但准确率稍差。分析其原因,主要是该算法不能区分模式的真正语义,因此,下一步的工作是对发现的模式进行进一步分析,以找到能提高算法准确率的有效方法。
参考文献:
[1] Zouaq A,Nkambou R.Building domain ontologies from text for educational purposes[J].IEEE Transactions on Learning Technologies,2008,1(1):49-62.
[2] Zouaq A,Nkambou R.Evaluating the generation of domain ontologies in the knowledge puzzle project[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(11):1559-1572.
[3] Maedche A,Staab S.Ontology learning for the semantic web[J]. IEEE Intelligent Systems,2001,16(2):72-79.
[4] Stojanovic L,Stojanovic N,Volz R.Migrating data intensive web sites into the semantic web[C]//Proceedings of the 17th ACM Symp.on Applied Computing.New York:ACM Press,2002:1100-1107.
[5] Astrova I.Reverse engineering of relational database to ontologies [C]//Proceedings of the 1th European Semantic Web Symposium.Heraklion,Crete,Greece,LNCS,2004:327-341.
[6] 高军,王腾蛟,杨冬青,等.基于Ontology的Web内容二阶段半自动提取方法[J].计算机学报,2004,27(3):310-318.
[7] 方卫东,袁华,刘卫红.基于Web挖掘的领域本体自动学习[J].清华大学学报:自然科学版,2005,45(S1):1729-1733.
[8] 于红,刘欣,尹祥贵,等.基于本体的渔业信息检索系统的研究与实现[J].郑州大学学报:理学版,2007,39(4):70-73.
Knowledge base based fisheries ontology learning algorithm
YU Hong,LIU Xi-jing
(School of Information Engineering,Dalian Ocean University,Dalian 116023,China)
Abstract:The ontology learning methods and their limits in fisheries are discussed.A knowledge base based fisheries ontology learning algorithm is proposed,and the proposed algorithm is featured in fisheries'conception into consideration.The algorithm is explained in detail,and the performance of the proposed algorithm was proved in the experiments in which the results were showed to be effective.
Key words:knowledge base;ontology learning;fisheries ontology
文章编号:2095-1388(2011)02-0168-05
中图分类号:TP311.133
文献标志码:A
收稿日期:2010-04-09
基金项目:辽宁省教育厅高等学校科研计划项目(05L090);大连市青年基金资助项目(2005J22JH038);大连海洋大学博士启动基金资助项目(sybs200712)
作者简介:于红(1968-),女,教授。E-mail:yuhong@dlou.edu.cn